Table of Contents:
- Lessons Learned
- Keep S3 Bucket Configurations Repeatable
- How To Determine S3 Object MIME Type Programmatically
- Namecheap Are Being Cheap
- ACM Certificates For Cloudfront Need To Live In N. Virginia
- How To Modify Static Code Through Terraform
- Debugging a Lambda Locally Using Docker
- Integration HTTP Method ≠ REST API HTTP Method
- How To Trigger A Workflow In A Different Repository
- Git Submodules Boilerplate
- Terraform Workflows Need A Remote State
- Conclusion
Briefly after finishing the Cloud Resume Challenge I discovered a few “Extensions” to the challenge were now provided. The extension which piqued my interest was the terraform one, due to the popularity of the Hashicorp technology among the community. The goal was simple: Convert your Infrastructure as Code (IaC) definition to terraform.
 In my case, this meant porting the AWS Serverless Application Model (SAM) Template to terraform configuration, so that it could be deployed using just
In my case, this meant porting the AWS Serverless Application Model (SAM) Template to terraform configuration, so that it could be deployed using just terraform init && terraform apply instead of the AWS-specific sam build && sam deploy workflow.
In late November, I was booked on a client assessment which included a terraform code review component, so what better opportunity to familiarise myself ahead of the job? So after just over a month and moments before 2022 waved goodbye, I completed the challenge extension and as part of step 15 I wrote a blog post to document what I learnt. The terraform clone of my Cloud Resume application can be found at https://resume.tf.laripping.com.
Lessons Learned
Keep S3 Bucket Configurations Repeatable
The first thing I noticed was that my existing infrastructure was by no means fully IaC-compatible, as the S3 bucket hosting my application’s frontend code (HTML/JS/CSS) was not managed by the SAM template. The bucket had been created manually once, and henceforth only its objects were updated through the frontent’s workflow. So, after starting fresh with some basic S3 bucket configuration, I opened both the old and new buckets side-by-side in the console and I slowly played around with the properties to make them identical. Obviously not the most elegant solution. For future reference, a more scalable alternative would be to import the existing resource to the terraform state.
How To Determine S3 Object MIME Type Programmatically
Later on during step 5 of the challenge, when uploading the frontend code as S3 objects, I bumped into an issue where terraform would automatically classify all uploaded files as binary/octet-stream. While my foreach loop (stolen from here) to pick up multiple files recursively was ok, there wasn’t a trivial way to specify the Content-Type / MIME type for each object automatically. This is where this brilliant blog post saved the day, demonstrating a way to programmatically specify the right Content-Type from the file extension, using a custom map:
{
".html":"text/html",
".js" : "application/javacsript",
".css": "text/css",
".png": "image/png",
".svg": "image/svg+xml"
}
And the terraform-fu to use it:
locals {
mime_types = jsondecode(file("${path.module}/data/mime.json"))
}
...
resource "aws_s3_bucket_object" "s3_upload" {
content_type = lookup(local.mime_types, regex("\\.[^.]+$", "index.html"), null)
}
Namecheap Are Being Cheap
As previously discussed, I had decided to build a new website instead of converting the existing one, keeping both applications active as reference proofs of concept (PoCs). When setting up the ACM certificate for the domain that the terraform application variant would sit on, I found out there’s a Namecheap terraform provider! That meant I could potentially also automate the non-AWS tasks involved in the setup:
- Creating a new CNAME record for my new subdomain (e.g.
resume.tf) - Creating the necessary CNAME records for the DNS validation that AWS would perform server-side All with the following terraform configuration:
terraform {
required_providers {
namecheap = {
source = "namecheap/namecheap"
version = ">= 2.0.0"
}
...
}
resource "namecheap_domain_records" "dns_records" {
domain = local.domain_name
mode = "MERGE"
record {
hostname = local.resume_subdomain
type = "CNAME"
address = aws_cloudfront_distribution.cf_distribution.domain_name
}
record {
hostname = aws_acm_certificate.cert.domain_validation_options.resource_record_name # might need to split(.laripping)[0]
type = "CNAME"
address = aws_acm_certificate.cert.domain_validation_options.resource_record_value
}
}
However, Namecheap thought otherwise:

So instead I just stole the validation targets AWS spit out from the terraform.tfstate file and confgured them on the Namecheap dashboard manually.
ACM Certificates For Cloudfront Need To Live In N. Virginia
While creating my certificate through terraform and keeping an eye on the console for the results, I noticed that the previous certificate I had generated for the original Cloud Resume Challenge was strangely under us-east-1… a region I would never deliberately use. Later down the road, a terraform error shed light on the exact reason for this:
 And it seemingly got worse…
And it seemingly got worse…
No migration options meant I would have to discard it and create it again in the right region, repeating the whole manual process of adding the CNAME records on Namecheap - a terrible development for the idempotency of my configuration!
But luckily, specifying the new ACM certificate in the new region (using a second provider block) led to the exact same CNAMEs to be requested for validation- not too shabby!
How To Modify Static Code Through Terraform
When more resources made their way into the terraform configuration, it became apparent that my backend code suffered from the classic rookie-DevOps mistake: Tight coupling. As it assumed that: 1. SAM would be used no matter what. But who uses SAM when there’s terraform? 2. The API URL and other cloud-depended identifiers would always be the same… And hardcoding is never a good idea.
For the second problem, I hacked together a Python script that would replace the API URL within the frontend’s JS code using plain old regex-fu. Not the best solution but it worked.
Additionally, I had to figure out a way to change the following identifiers within the Python code of the backend:
- The DynamoDB table name that the Lambda would query/insert in
- The application domain name that would be used as the only allowed Origin Here, I picked the recommended path and refactored the code to expect environment variables for these identifiers - environment variables that could (would, and actually should) be passed to the Lambda function during runtime.
Debugging a Lambda Locally Using Docker
Now, for the first problem found before - the SAM deployment steps being intertwined with the develoment of the Lambda function code - I had to find a workflow for local debugging independent of the SAM CLI. Effectively, I needed to simulate a “Lambda-like” environment on my development machine to wrap the code within. After tryng to take a shortcut with the python-lambda-local library and failing, as it kept timing out on all operations attempted, I went with the AWS-endorsed solution of using a Docker image to simulate the Lambda runtime.
In the process of developing the Dockerfile for this container, I bumped into another classic problem: How do you authorise local code to perform AWS operations? A problem I had seen in client engagements too. The solution? IAM Roles, of course. The container would assume the IAM role destined for the Lambda function, allowing it to interact with the AWS environment exactly like the Lambda code would.
But how do I limit the entities allowed to assume the Lambda’s IAM role, to the container only? How do I even declare a local container in AWS-speak in first place? It isn’t exactly an AWS “Service”.
The available choices for this decision were well described, so I opted to go for an AWS account filter, thereby allowing all entities within my own account to assume the role. This way all that’s required during development is an AWS user (configured by means of an ~/.aws/credentials profile) to assume the Lambda’s IAM role. Then the temporary tokens generated would be passed to the container. To automate this process, I hacked together another quick bash script that - assuming AWS authentication - would retrieve a temporary token for a given IAM role, i.e. performing AWS authorisation, and save it into a file specified by the user:
Integration HTTP Method ≠ REST API HTTP Method
Another lesson learned after hours of painful debugging came up during the final, complete deployment and end-to-end testing, by visiting the website. This one took me deep down the rabbit hole but shed some light on the black-box integration of a Lambda function with the API Gateway service.
It started with the familiar, super-informative “500 - Internal Server Error” response from the API indicating I had messed something up in the Python code. What made this even weirder though was that testing the same Lambda code both locally (using the container) and through the AWS Console’s “Test” feature gave out the expected, correct results, error-free. My first thought was to look for logs, but funny enough, there wasn’t even a CloudWatch log group for the new Lambda - a resource that should have been created automatically for both the SAM-managed Lambda and the present terraform one. According to the documentation, the permissions of the Lambda’s IAM role should create the log group automatically if appropriately configured, which they were. Google told me this was probably a problem with terraform’s dependency graph, as editing the IAM role later down the line could deprive terraform of the opportunity to create and manage the log group. So here was my chance to tick step 14 of the challenge etension.

Destroying everything and re-creating it from scratch would constitute a good test of resiliency, uncover other potential issues with the repeatability of my configuration, and give terraform a chance to create and manage the log group for the Lambda. Frightened, I typed the commands terraform destroy && terraform apply on my terminal and watched anxiously. Surprisingly, it worked great; everything was re-created hassle-free, with just one expected exception: a CNAME record for the old CloudFront distribution had to be manually deleted from my Namecheap dashboard. Considering I was using an external DNS provider that terraform could do nothing about, this was a natural result. However, the issue I initially intended to solve persisted; a 500 error code from the API with no logs.
I decided to momentarily cheat and created the CloudWatch log group myself, via the console. But even then, re-running didn’t yield any logs. It was time to pull up my sleeves. Breaking it down in my head - if the Lambda worked fine on its own and only failed when accessed through the end-to-end flow i.e. through the API Gateway service - it seemed the perpetrator was in fact the API Gateway. Looking into debugging options, I went on to enable “Execution logs” for the API and attach an IAM role to the REST API so that the API Gateway service can post logs to CloudWatch. This seemed to give sligthly more info… but still, not the cause of the issue. I was getting closer.
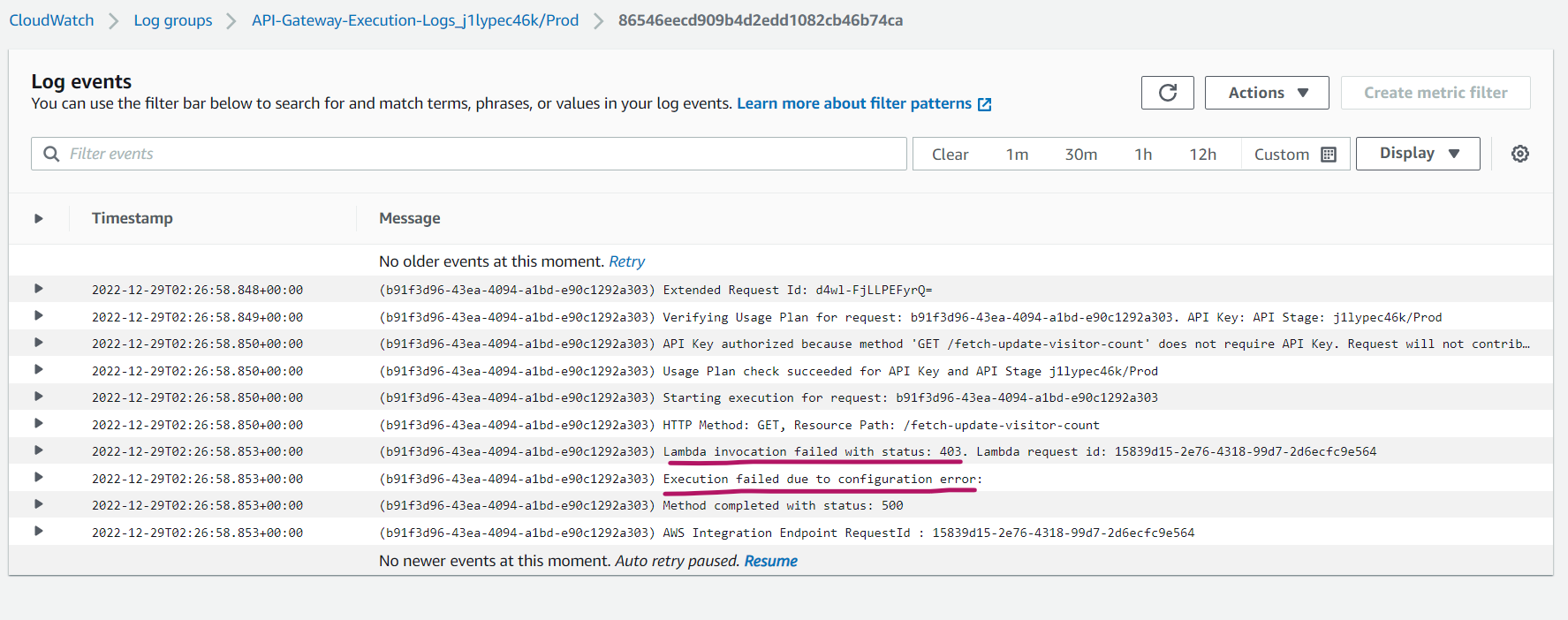
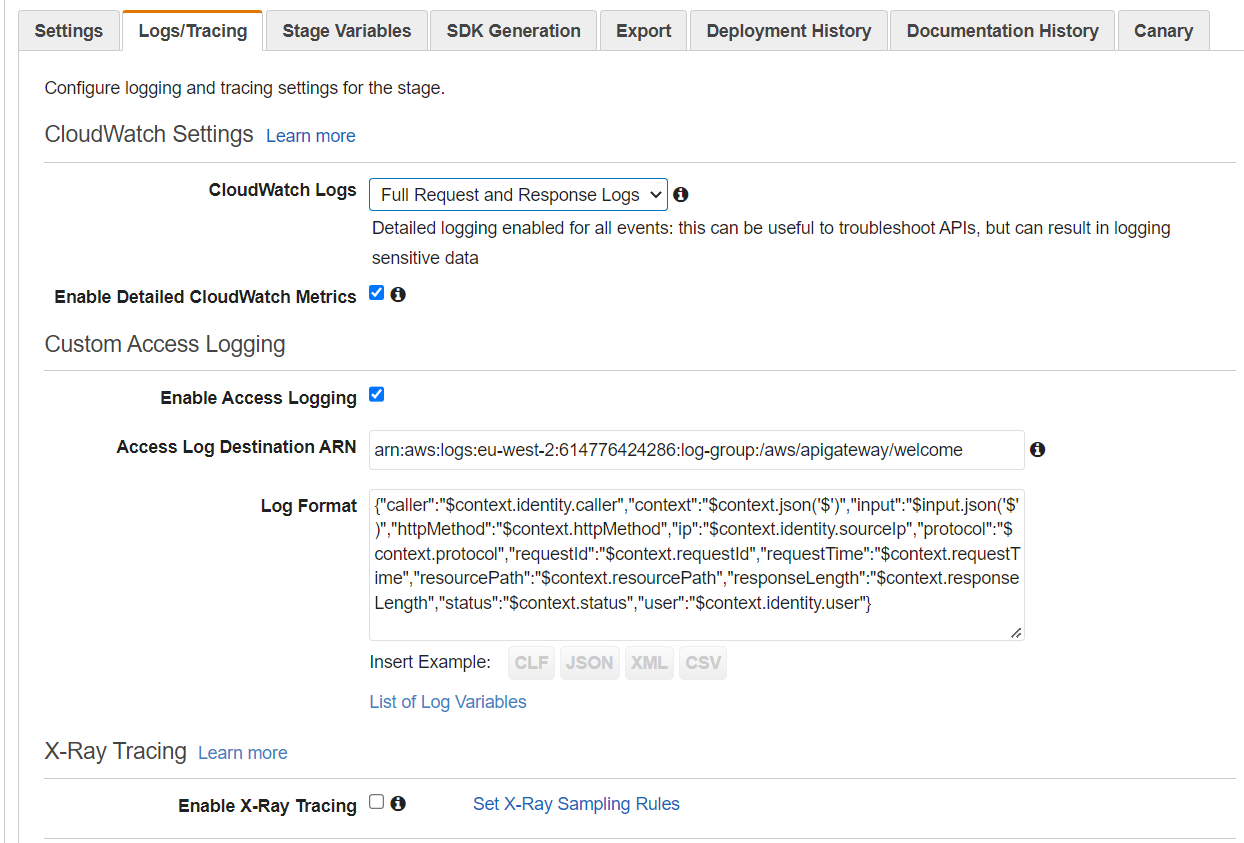
The next step was to fully open the tap, by switching the execution logging to the highest possible verbosity, and dump everything I could in the log messages:
Finally, I could see some meaningful log messages. One even revealing the underlying problem:
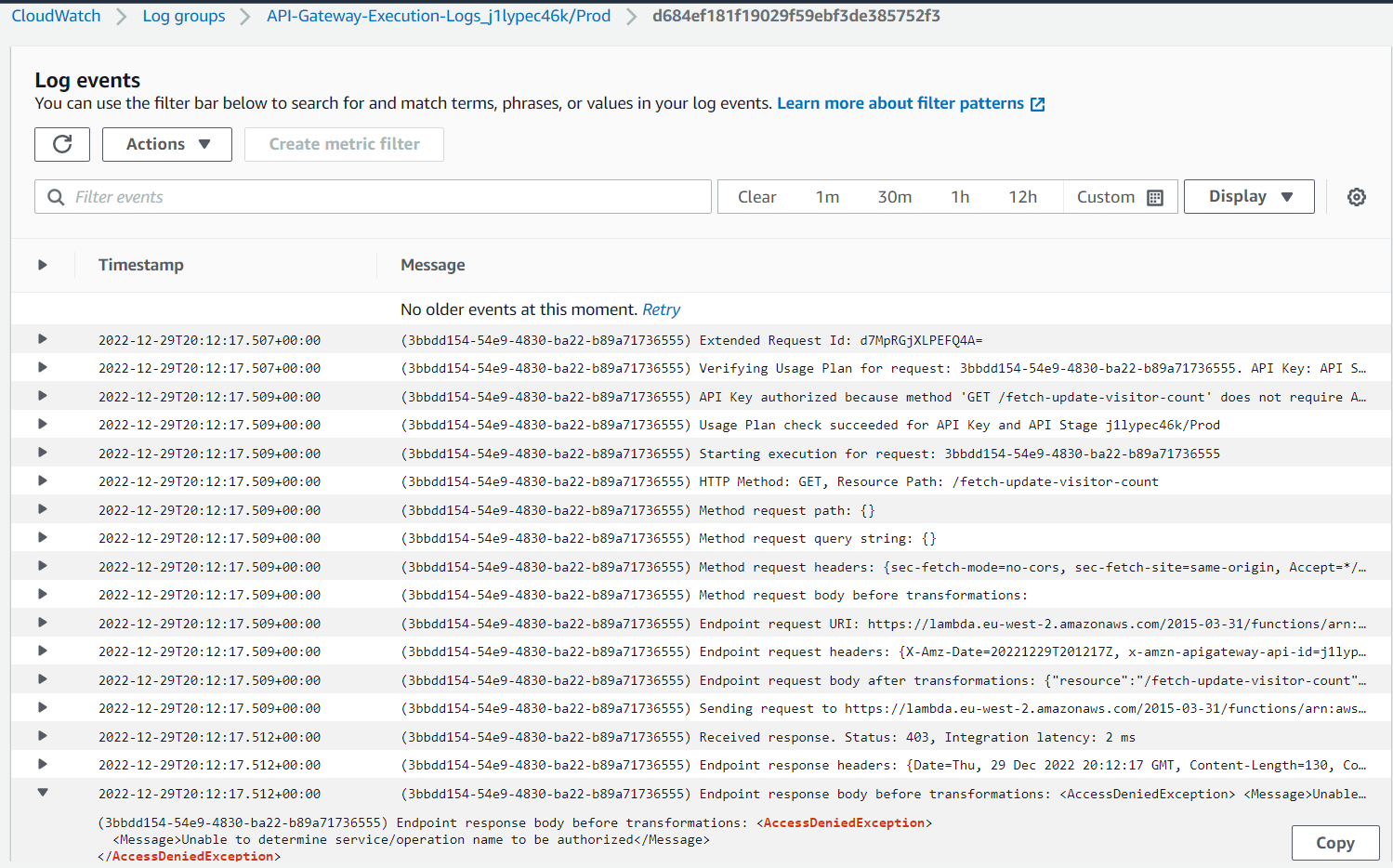
Essentially, this error message indicated that the suspect was the “API Integration HTTP Method”. My relevant terraform configuration, proudly copypasted by the AWS provider’s documentation, was the following:
resource "aws_api_gateway_integration" "api_int" {
http_method = aws_api_gateway_method.api_method.http_method
type = "AWS_PROXY"
integration_http_method = "GET" #!!!!
...
}
Notice how there’s both an http_method and an integration_http_method argument. If one’s for the REST API what is the other for? As the article linked above taught me, this is an intermediate request which the API Gateway issues to invoke the Lambda’s pseudo-REST API. And this later one needs to be a POST request. Gotcha. Changing this parameter fixed the issue right away!
How To Trigger A Workflow In A Different Repository
The final step of the challenge was to push the terraform code to Github and leverage Github Actions to trigger automatic deployment of the infrastructure upon changes of this terraform code.
I took a slightly different approach here, and decided I would instead trigger the terraform apply upon changes to the actual code of the application, versioned in the cloud-resume-frontend and cloud-resume-backend repositories, versioned under dedicated terraform branches - to keep the SAM workflow (on master) intact and working. Nevertheless, it seemed fitting to have the terraform-specific build pipeline defined under the terraform repository cloud-resume-terraform. So I needed a way to trigger remote workflows across different Github respositories, all owned by the same account.
Easy enough, this problem had been encountered before, and the solution was to leverage the Github API, to send a “repository dispatch” from the frontend/backend workflows, to the terraform repo. All the child workflows needed was a (fine-grained) Github API Personal Access Token Neat (PAT) configured in their secrets to trigger the remote workflow:
curl -vv -XPOST \
-H "Authorization: Bearer github_pat_...." \
-H "Accept: application/vnd.github.everest-preview+json" \
-H "Content-Type: application/json" \
https://api.github.com/repos/LAripping/cloud-resume-terraform/dispatches \
--data '{"event_type": "tf_build", "client_payload":{"source":"terminal"}}'
Git Submodules Boilerplate
When working on this Cloud Resume Extension I also finally had a chance to work with another feature I knew existed but had never familiarised with: git submodules. Initially, to give terraform access to:
- the frontend code which it needed to upload to the S3 bucket,
- and the backend code which it needed to create the Lambda function with
I had opted to git clone the repos manually in the same directory. Leet skillz, I know. When the time came to fix this, I knew it was high time to tackle this beast too.
So after diligently Reading The Feature Manual (RTFM) I found the necessary commands for my use-case, which have been pasted below for future reference:
git clone parent-repo && cd parent-repo
# This will only create the .gitmodules indicating there are submodules involved, and an empty directory for the child...
git submodule add -b child-branch child-repo
# to get the child code, you also need
git submodule init && git submodule update
# or, if starting from scratch (like in my tf deploy workflow)
git clone --recurse-submodules parent-repo $$ cd parent-repo/child-repo/src/...
# make edits on parent-repo code, commit/push them, then update the parent's pointers
cd parent-repo && git add child-branch && git commit
Terraform Workflows Need A Remote State
When trying to terraform apply from within the GH Action, I had to finally pay another installment of my technical debt: To avoid creation of a duplicate infrastructure, the terraform state had to be migrated to a remote backend. A place where the terraform CLI from within the Github Action would be able to see it.
terraform {
...
backend "s3" {
bucket = "tf-remote-state-manual"
key = "crc-terraform.tfstate"
region = "eu-west-2"
}
}
From the available state backends, I chose the most common, the S3 bucket backend, and created another IAM role on my AWS account that terraform would assume. After adding the code above and creating the S3 bucket manually, migration was performed smoothly and silently after just a terraform init. The only problem with this solution is that the IAM user created for the terraform CLI on the workflow ended up being a bit too powerful… While that makes sense given the powers of terraform and the tradeoff against the ease of use, some cutting could definitely be introduced maybe to reduce the resources allowed or apply a privilege boundary.
Conclusion
Terraform is a truly awesome technology with endless use-cases, surprisingly stable and resilient and really easy to use. All while staying vendor-agnostic and thus superior to vendor-specific solutions like the SAM CLI, enabling organisations to manage multi-cloud environments unconditionally. One would assume these are the reasons why it is widely adopted by the community and heavily extended through numerous providers.
Once again, the Cloud Resume series of challenges provided a great way to learn-by-doing. Special thanks to Roseary Wang and Kerim Satirli for contributing the terraform extension and making terraform more accessible to people preferring a practical way to familiarise themselves, over a daunting thousand-page documentation site.
Thanks for reading!